Quote:
All this is because we start in wrong direction. But somehow this actually works.
I am sure that totally different techniques are used in other processors.
Current beta is actually best for now, and shure better then yesterday (hold time?) Less difference between hard compressed tracks and tracks with high rms/peek ratio.
I checked v5.0 and 4.22 versions, all actually do same thing .. lowers voices when it should not. That is why once asked for compressor after AGC, or kind of limiter or something, but again singleband compressor in ST is not actually real compressor, and long trip will be to make sidechain compressor or wb compressor .. or.. Once i ask for Final Limiter .. bands, ratio, lookahead...and still not sure how it works.
brrmm
Just thinking aloud here...
Basically, as long as all the sounds at all different frequencies stay within the same volume range, everything is fine.
Now if a single (or a few, in case of voices) frequency stands out - be it bass, a loud voice, whatever - we get in trouble.
For example, a loud voice in that Celine Dion track looks like this:
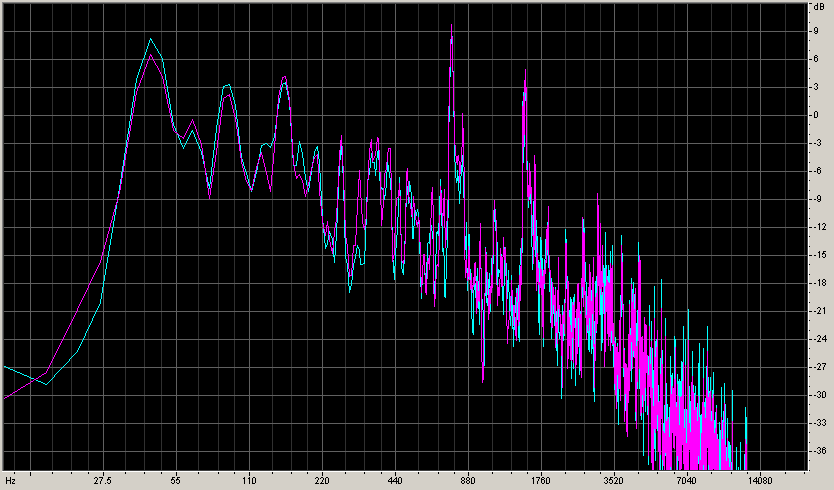
Here you can see why in this case the bass is actually helping to keep the volume constant!
Equalizing it according to ITU-1770 makes things even (a lot) worse:
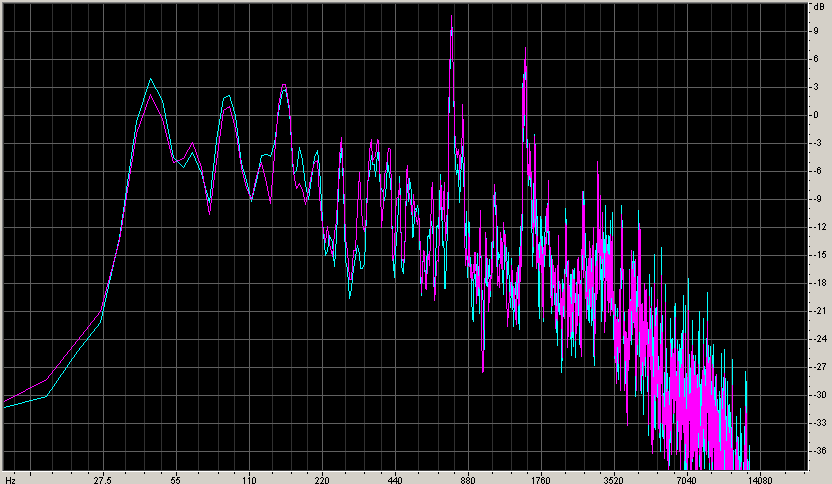
The bass is lower, and the voice peak is higher, which makes things a lot worse.
Another troubling sound is Beyonce - Video Phone:
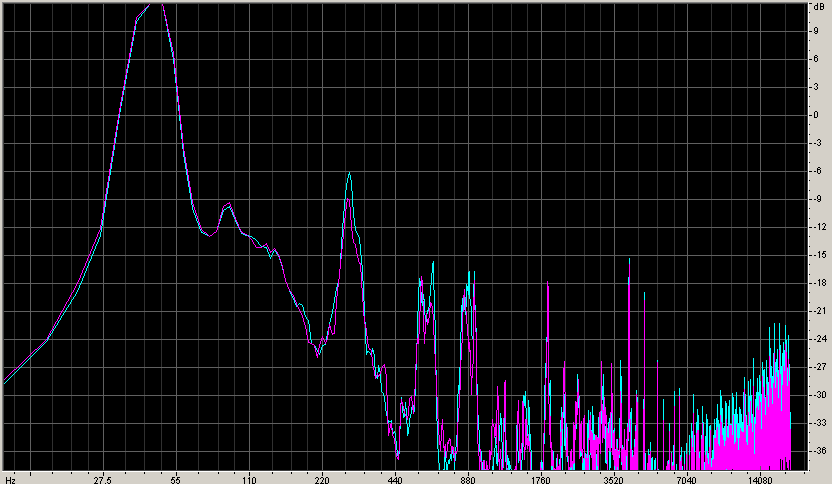
Which gets better when using ITU-1770 processing, but still contains an insane amount of bass.
That would lead to the following solution:
- I measure the frequency content of the input signal
- I find the 'normal' peak level (have to think of a calculation for that...)
- Using that, I calculate a 'maximum' peak level
- And then I kill everything that's louder than this maximum level (well, kill is too much. But I can reduce it by a number of dB's)
If I do that, I would process Video Phone without the bass. And Celine Dion without... Celine Dion

Most other sounds should not be affected at all.
But: This would lead to other weird things. For example, if I have a beep tone with other sounds, and everything but the beep disappears. Then I would start reducing the beep (for measurement purposes), and - in reality - boost its volume way too high. That could be solved by ONLY using this new level to determine if the volume should go down, and use the real levels to determine if it should go up.
But: Say there's only this beep tone, and the volume is already very high (the beep didn't cause it to drop). Then, when other sounds are added, suddenly the beep isn't dropped anymore and the total volume drops very strongly (because it didn't before). Yuck.
And if there's only a voice, the volume
should be dropped if it gets loud.
Basically this is an unsolvable problem. I need to be able to distinguish "a very loud portion of this track starts to play, I need to very rapidly drop the volume" from "Oh, it's just Celine Dion, she'll shut up in a second, just ignore her". Without looking ahead (and the look-ahead time would have to be multiple seconds).
Still thinking... Ideas are welcome...
Edit: What would happen if band 1 does not respond to Celine Dion? So the volume below 200 Hz wouldn't drop if she starts to sing? Would that improve things? Just like band 2 is locked to never get lower than band 1, I could add a band where I only process bass and lock band 1 to that...
